-
[JPA] 영속성에 대한 초간단 테스트Spring/JPA 2023. 4. 6. 17:02
JPA의 영속성에 대해 공부하면서 생긴 궁금증들을 직접 실험하고 알아보는 시간을 가졌습니다.
* 내용 오류, 오탈자 피드백은 언제나 감사하게 받고 있습니다. 확인 후 수정하도록 하겠습니다.
해당 포스팅에 사용된 Repository는 다음과 같이 상속받고 있습니다.

1. @Transactional
영속성 컨텍스트를 사용하려면 @Transactional을 꼭 사용해야 할까요?

1-1. @Transational 사용 여부에 따른 조회
1) @Transactionl 없음

동일 쿼리 3번 조회
2) @Transactionl 있음

쿼리 1번 조회
3) 두 메소드의 호출 순서에 영향이 있을까?
-> 결과적으로 두 메소드의 호출 순서에 따른 쿼리 조회 횟수는 변화가 없었습니다.
해당 결과로 보았을 때, @Transactional이 붙어있는 메소드 범위까지 영속성을 관리하는 것으로 예측됩니다.
그렇다면 직접 호출하는 메소드보다 상위에 @Transactional이 있으면 영속성의 범위가 확대될지 궁금해집니다.
1-2. @Transactional의 위치
1) 호출 최 상위 메소드에 @Transactional 사용하기

쿼리 1번 조회
-> 1-1 에서 하위 메소드들 (noTransactional과 transactional)을 동일하게 호출하지만, 해당 테스트 메소드에 존재하는 @Transactional까지 영속성의 범위가 확대되었습니다.
그렇다면, @Transactional 사용 여부에 따라 결과가 달라지는 이유가 무엇일까요?
미리 결과를 말하자면 findById의 내부에서 엔티티매니저를 사용하고 있기 때문입니다.
어노테이션을 사용하지 않은 경우, 매번 새로운 엔티티 매니저를 생성하여 조회하였겠지만, @Transactional을 사용하여 동일한 엔티티 매니저에서 조회할 수 있었기 때문에 조회 횟수에 차이가 있습니다.
이렇듯 @Transactional을 사용하면 트랜잭션 범위 내에서 동일한 영속성 컨텍스트를 사용할 수 있도록 명시해주고, 트랜잭션의 범위를 확대할 수 있습니다.
2. List도 영속성을 가질까?
영속성을 머릿속으로 그려보던 찰나 항상 findById로 영속성을 실험하지만, List로 영속성을 실험하는 글을 본 적이 없다는 생각이 들어서 직접 해보았습니다.
상위 호출메소드에는 @Transactional을 사용하지 않고, 각 메소드에만 @Trnasactional을 사용하였습니다.
2-1. 결과로 List를 가져오는 메소드 조회
1) findAll

동일 쿼리 3번 조회
2) findAllById

동일 쿼리 3번 조회
-> List를 조회해도 영속성을 가지고 있어서 새로운 쿼리 조회가 없을 것이라고 예상했던 것과 달리, 메소드의 사용 갯수만큼 DB조회가 이루어졌습니다.
여기서 주의할 점은 '1차 캐시에 존재하면, DB 조회가 이루어지지 않는다'는 문장이 '모든 메소드에서 1차 캐시에서 해당 엔티티 존재 여부를 확인한다.' 와는 다르다는 것입니다. 1차 캐시에서의 해당 엔티티 존재 여부를 모든 메소드 내부에서 확인할지는 모른다는 것 입니다.
영속성과 함께 설명하는 entityManager의 find와 우리가 JpaRepository를 통해 사용하는 findAll과는 다른 메소드입니다. JpaRepository를 상속받는 객체에서 사용하는 메소드가 실제로는 SimpleJpaRepository의 구현체입니다.
실제로 findAll을 디버깅하면 해당 메소드를 실행하게 됩니다. (findAllById도 마찬가지로 아래 로직 실행))

리턴하는 행의 가장 마지막을 보면 em.createQuery가 존재하는데, 해당 메소드는 매개변수로 받은 query를 JPQL로 전환하여 DB에서 조회를 하는 로직을 가지고 있습니다.
따라서, findAll과 findAllById에서는 1차 캐시를 조회하지 않고, JPQL을 실행하기 때문에 동일한 쿼리를 계속해서 조회했다는 것을 알 수 있습니다.
2-2. Id로 하나의 결과만 조회
그렇다면 예시로 자주 사용되는 findById를 사용해봅시다.
1) findById

쿼리 1번 조회
예상대로 findById는 한 번만 DB 조회가 이루어졌습니다. findAll과의 차이점은 SimpleJpaRepository에서 찾아보겠습니다.
아래 코드는 SimpleJpaRepository의 findById입니다.
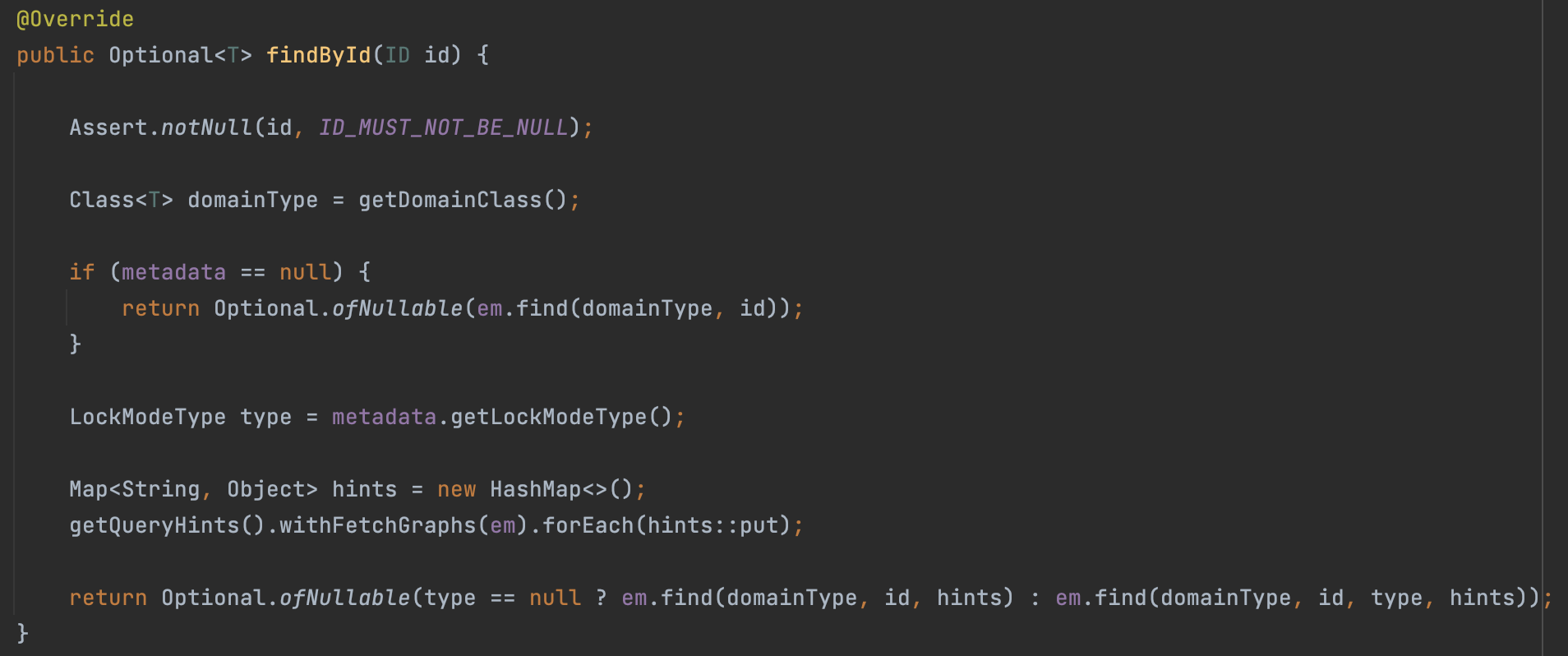
이 중 가장 마지막 줄인 em.find에서 1차 캐시에 존재하는지 확인 후, 존재하지 않으면 DB를 조회하고 결과를 1차 캐시에 저장하는 동작이 일어납니다. 그렇기 때문에 첫번째 findById에서 결과를 1차 캐시에 저장하고 이후의 findById 요청은 1차 캐시의 엔티티 인스턴스를 사용하는 것 입니다.
2-3. List 와 엔티티 함께 사용하기
그렇다면 List의 결과는 영속성을 가질까요?
JPQL로 리턴된 결과 또한 영속성을 가집니다. 그렇다면 앞서 사용한 List를 리턴하는 메소드와 Id로 검색하는 메소드를 하나의 트랜잭션 안에서 함께 사용하면 어떨까요?
1) findAll + findById
메소드를 재활용하기 위해 상위에 @Transactional을 사용하였습니다.

동일 쿼리 3번 조회
findAllTransaction() -> 3회
findById() -> 0회
2) findAllById + findById
메소드를 재활용하기 위해 상위에 @Transactional을 사용하였습니다.

동일 쿼리 3번 조회
findAllByIdTransaction() -> 3회
findById() -> 0회
findAll과 findAllById 내부에서 JPQL로 DB를 조회하고 List 결과를 1차 캐시에 저장하기 때문에, 캐시 이미 저장되어 있는 id로 조회를 하면 추가적인 DB 조회없이 캐시의 엔티티 인스턴스를 사용할 수 있습니다.
결과적으로 JpaRepository를 상속받고 있는 repository를 이용하는 경우, 실제 메소드 내부에서는 1차 캐시를 확인하지 않는 케이스가 있다는 것을 알 수 있었습니다.
'Spring > JPA' 카테고리의 다른 글
[JPA] 언제 N+1이 발생할까? (0) 2023.06.22 [JPA] 엔티티 연관관계 매핑 테스트 (2) : @Embedded, @ElementCollection 사용해보기 (0) 2023.04.25 [JPA] 엔티티 연관관계 매핑 테스트 (1) : @OneToMany, @ManyToOne (0) 2023.04.23